Cloud native incident response in AWS - Part I
Introduction
Welcome to our latest blog, it has been a while. In this series we are going to be discussing something that we are very passionate about, native cloud incident response in an AWS environment. As for the structure of this series, in the first part we will go over the approach that you can take when responding to an incident. In the next part we will go deeper into the logs we often see in AWS and show you how to analyse them with our favourite solution for cloud native incident response.
Want to level up your cloud incident response game? Register now for our AWS incident response course and you will be alerted when it goes live.
Background
As a cloud incident response company we see our fair share of incidents, in the past year(s) we have published two write-ups of incidents in AWS environments. One about ransomware in the cloud and one about a long-term compromise with lots of interesting tactics. Interestingly enough these blogs are the two with the most views, there seems to be a big interest in learning more about incidents in AWS environments. When doing cloud incident response, you will quickly find out how critical logs are for your investigation. In this series we are going to show you how we perform incident response in the cloud and the choices you can make. We are writing this series from a viewpoint of an external services provider, which means that the most important thing for us is, how can we deliver as much value as possible in the shortest amount of time.
Approach
There are several options available when working on an incident response in an AWS environment. You can use the decision tree below to make your choice as to what works for you. There are two things you need to understand before you start:
- What logging is available?
- Where are the logs stored?
Log availability & storage
In the below picture a non-exhaustive list of logs that we often use during incident response. You can also use our tool Invictus-AWS to help you identify the logs that are available. Once you know what is available you need to understand where the logs are stored, why is that so important? Well the services we will discuss for analysis can interact directly with S3 storage. So if the logs are not stored there you will need to move them to S3 in order to make them available for analysis. If they are already in S3 you don't need to move the data and you can directly go to analysis.
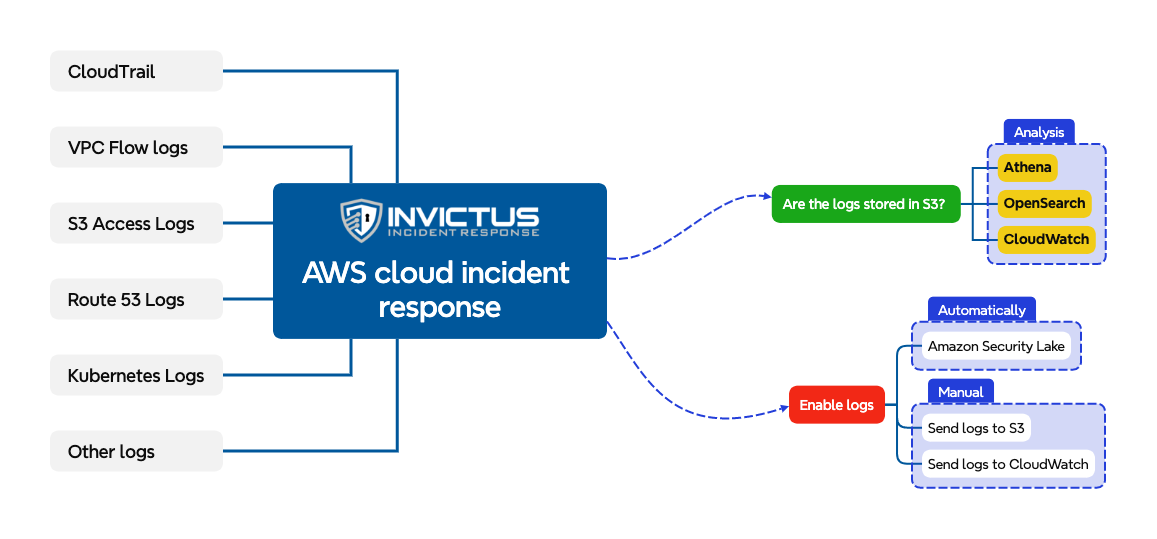
Let's discuss the services and their pros and cons.

CloudWatch
Most AWS services directly integrate with CloudWatch as a log destination, which is why it can be useful in an where it’s enabled. In some cases it's also automatically enabled for services to send logs to CloudWatch, for example Lambda. Below some services that integrate with CloudWatch.
- CloudTrail
- VPC flow logging
- Route 53
- Amazon EKS (Kubernetes)
- AWS Lambda
Pros:
- Support for major AWS services that you might come across during incident response
- Easy to setup and configure, most of the time it will already be there for services you are investigating
- Supports forwarding data to S3, this allows you to potentially also use other services like Athena for analysis
- Supports streaming data to OpenSearch, so you can use that for analysis
Cons:
- Point-in time forward, the biggest drawback is that there's no support for historical data searches meaning that if it wasn't configured correctly when the incident occured you can't load in old logs*
- Limited query language, the query language isn't great for analysis, manipulation and aggregation
- Costs, you are charged for ingestion, storage and retention of data, on top of that if you retrieve the data out of CloudWatch (e.g. send it to S3) you will also incur charges
* Technically you can ingest old logs, but it's quite hacky and not what the service is intended for

Athena
With Athena you can load in any data you want and query it with SQL which makes it really powerful, especially because it's a serverless offering so all you have to do is point to your S3 bucket with logs and you are good to go. This is super useful in incident response when every second counts. Combined with the fact that there's great documentation for all major log sources in AWS there's little drawback in using this service.
Pros:
- Very flexible supports all major logs and there is documentation for all the logs on how to load the data
- Query language is SQL, making it easy to use and lots of learning resources and samples available to build queries
- Works on historical data, just point it to an S3 bucket and define the fields in the log and it will load in the data
- Support for custom logs, this does require writing your own loading instructions, but if you know your data it can be very powerful to load in your own logs stored in S3
Cons:
- Costs, writing bad queries punishes you hard because you will be charged for data scanned with Athena. So if you decide to do SELECT * FROM CloudTrail you might be in for a surprise

OpenSearch
It's not Elasticsearch it's OpenSearch.... If you want to get a full blown log management solution this is the way to go. Before you can use OpenSearch you must configure your log sources to forward their data to OpenSearch. Once they are in there you can start writing your queries, building visualisations and dashboards. You will most likely only use this in incident response engagements when your company or client has this already configured.
Pros:
- Powerful search language with enrichment options basically all the good things from Elasticsearch
- Fast searching on large datasets, because you control the underlying hardware
- Visualisations and dashboarding options in OpenSearch, which can be very useful for incident response engagements
Cons:
- Setup and configuration takes time and planning, you need to create a cluster before you can use this and if you don't know what data is coming in or how much that is not ideal
- Costs, running OpenSearch is (very) expensive in our experience even a small cluster can be costly especially when compared to Athena/CloudWatch
- Indexing, data needs to be indexed first in OpenSearch before you can search it
(Bonus) CloudTrail Lake
There is also another option, but it's only useful if your analysis is limited to CloudTrail. In that case you can also use CloudTrail Lake, it is a data lake solution for just CloudTrail. There are to major challenges if you want to use this for incident response:
- Doesn't work on historical logs
- Limited to CloudTrail logs only
Conclusion
If you've made it this far I hope you learned something about the options you have when faced with an incident response in an AWS environment. Our prefered solution is Athena for the following reasons:
- Speed, it doesn't require data loading just point to your bucket and the logs can be searched
- Support, it supports basically all logs we will ever need for incident response
The biggest drawback of CloudWatch and CloudTrail Lake is that they don't support historical logs which is not convenient when doing incident response as you will often need to look at historical logs. For us, the advantages of using OpenSearch are outweighed by the drawbacks of having to set up and manage the cluster, as well as the need to index the data.
Next week we will use Athena and show you how to load in all your favourite logs and search them within a minute or two....
About Invictus Incident Response
We are an incident response company and we ❤️ the cloud and specialise in supporting organisations facing a cyber attack. We help our clients stay undefeated!
🆘 Incident Response support reach out to cert@invictus-ir.com or go to https://www.invictus-ir.com/24-7
Be ready for the next cloud incident.
